Apache Spark es un marco computacional de código abierto para datos analíticos a gran escala y procesamiento de aprendizaje automático. Admite varios lenguajes preferidos, como Scala, R, Python y Java. Proporciona herramientas de alto nivel para transmisión de chispas, GraphX para procesamiento de gráficos, SQL, MLLib.
En este artículo, conocerá la forma de instalar y configurar Apache Spark en ubuntu. Para demostrar el flujo en este artículo, he usado el sistema de versión Ubuntu 20.04 LTS. Antes de instalar Apache Spark, debe instalar Scala y Scala en su sistema.
Instalación de Scala
Si no ha instalado Java y Scala, puede seguir el siguiente proceso para instalarlo.
Para Java, instalaremos Open JDK 8 o puede instalar su versión preferida.
$ sudo apt update
$ sudo apt install openjdk-8-jdk
Si necesita verificar la instalación de Java, puede ejecutar el siguiente comando.
$ java -version

En cuanto a Scala, Scala es un lenguaje de programación funcional y orientado a objetos que lo combina en un solo conciso. Scala es compatible tanto con el tiempo de ejecución de JavaScript como con JVM, lo que le otorga un fácil acceso al ecosistema de bibliotecas grandes que ayuda a construir un sistema de alto rendimiento. Ejecute el siguiente comando apt para instalar scala.
$ sudo apt update
$ sudo apt install scala
Ahora, verifique la versión para verificar la instalación.
$ scala -version

Instalación de Apache Spark
No existe un repositorio apto oficial para instalar apache-spark, pero puede precompilar el binario desde el sitio oficial. Use el siguiente comando wget y enlace para descargar el archivo binario.
$ wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Ahora, extraiga el archivo binario descargado usando el siguiente comando tar.
$ tar -xzvf spark-3.1.2-bin-hadoop3.2.tgz
Por último, mueva los archivos Spark extraídos al directorio /opt.
$ sudo mv spark-3.1.2-bin-hadoop3.2 /opt/spark
Configuración de variables de entorno
Su variable de ruta para chispa en su .profile en el archivo necesario para configurar para que el comando funcione sin una ruta completa, puede hacerlo usando el comando echo o hacerlo manualmente usando un editor de texto preferible. Para una forma más fácil, ejecute el siguiente comando de eco.
$ echo "export SPARK_HOME=/opt/spark" >> ~/.profile
$ echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile
$ echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profile
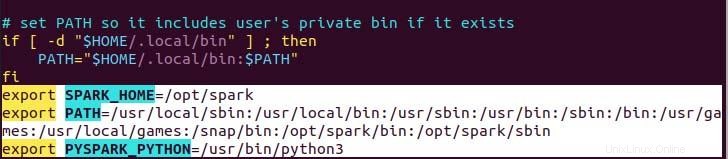
Como puede ver, la variable de ruta se agrega en la parte inferior del archivo .profile usando eco con>> operación.
Ahora, ejecute el siguiente comando para aplicar los nuevos cambios en las variables de entorno.
$ source ~/.profile
Implementación de Apache Spark
Ahora, hemos configurado todo, podemos ejecutar el servicio maestro y el servicio de trabajo con el siguiente comando.
$ start-master.sh
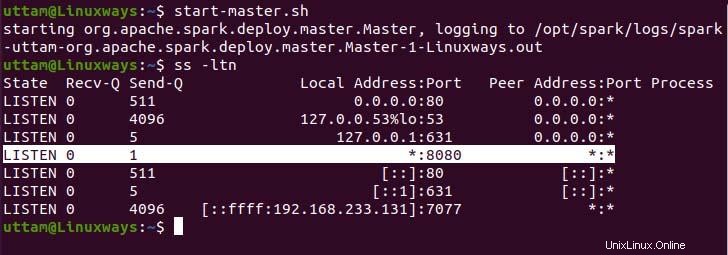
Como puede ver, nuestro servicio Spark Master se ejecuta en el puerto 8080. Si navega por el host local en el puerto 8080, que es el puerto predeterminado de Spark. Es posible que encuentre el siguiente tipo de interfaz de usuario cuando navegue por la URL. Es posible que no encuentre ningún procesador de trabajo en ejecución iniciando solo el servicio maestro. Cuando inicie el servicio del trabajador, encontrará un nuevo nodo enumerado como en el siguiente ejemplo.
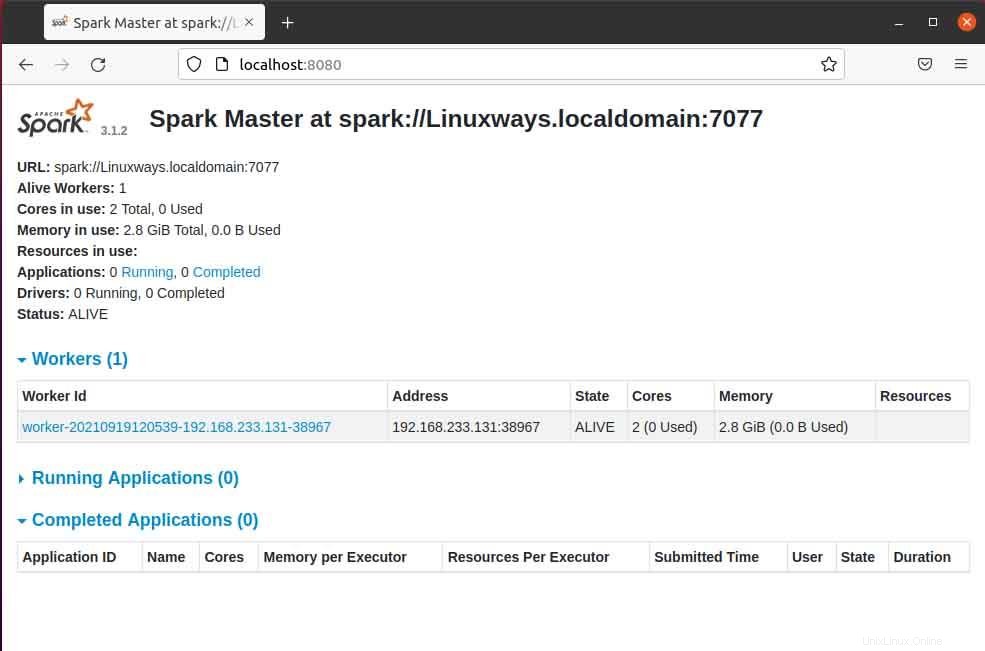
Cuando abre la página maestra en el navegador, puede ver spark master spark://HOST:PORT URL que se utiliza para conectar los servicios de trabajo a través de este host. Para mi host actual, mi URL principal de chispa es spark://Linuxways.localdomain:7077, por lo que debe ejecutar el comando de la siguiente manera para iniciar el proceso de trabajo.
$ start-workers.sh <spark-master-url>
Para ejecutar el siguiente comando para ejecutar los servicios de trabajo.
$ start-workers.sh spark://Linuxways.localdomain:7077

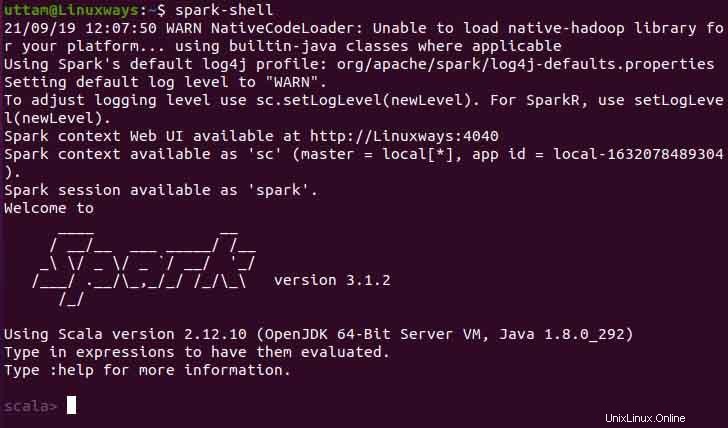
Además, puede usar spark-shell ejecutando el siguiente comando.
$ spark-shell
Conclusión
Espero que con este artículo aprenda la forma de instalar y configurar apache spark en ubuntu. En este artículo, intenté que el proceso fuera lo más comprensible posible.