Introducción
Las bases de datos NoSQL nos permiten almacenar grandes cantidades de datos y acceder a ellos en todo momento, desde cualquier ubicación y dispositivo. Sin embargo, es difícil decidir qué técnica de modelado de datos se adapta mejor a sus necesidades. Afortunadamente, existe una técnica de modelado de datos para cada caso de uso.
En este tutorial, cubriremos todas las diferentes técnicas de modelado de datos NoSQL que puede usar al crear su base de datos NoSQL.

¿Qué es un modelo de datos NoSQL?
NoSQL o 'No solo SQL' es un modelo de datos que difiere marcadamente de las expectativas tradicionales de SQL.
La principal diferencia es que NoSQL no utiliza una técnica de modelado de datos relacionales y enfatiza el diseño flexible. La falta de requisitos para un esquema hace que el diseño sea un proceso mucho más simple y económico. Eso no quiere decir que no pueda usar un esquema por completo, sino que el diseño del esquema es muy flexible.
Otra característica útil de los modelos de datos NoSQL es que están diseñados para una alta eficiencia y velocidad en términos de crear hasta millones de consultas por segundo. Esto se logra al tener todos los datos contenidos en una tabla, por lo que las UNIONES y las referencias cruzadas no son tan pesadas para el rendimiento.
NoSQL también es único porque es escalable horizontalmente , en comparación con SQL, que solo es escalable verticalmente. Con NoSQL simplemente puede usar otro fragmento, que es barato, en lugar de comprar más hardware, que no lo es.
Cuatro tipos de bases de datos NoSQL
En términos generales, existen cuatro tipos diferentes de bases de datos NoSQL, con docenas de modelos de datos basados en ellas:
Almacén de clave-valor
Construido específicamente para requisitos de alto rendimiento, y probablemente uno de los modelos de datos más comunes, los almacenes de clave-valor utilizan valores clave con punteros para almacenar datos.
Este puntero es único y se vincula directamente a una parte de la información, que puede ser cualquier cosa que le gustaría que fuera. Si lo desea, incluso podría usar una cadena vacía como clave de valor, aunque existen límites superiores para el tamaño de un valor según la base de datos.
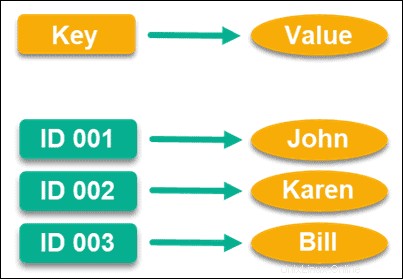
Curiosamente, fue Amazon quien originalmente ayudó a poner en marcha este modelo de datos y lo usan para DynamoDB. Dado que son uno de los mercados en línea más grandes del mundo, puede ver cuán alto rendimiento puede ser este modelo de datos.
Tienda basada en documentos
Con SQL, XML y JSON tienden a estar vinculados, lo que ralentiza las consultas y dificulta todo el proceso. Dado que NoSQL no usa el modelo relacional, no necesita hacer eso, que es donde entran las tiendas basadas en documentos.
Todos los datos se almacenan en una tabla, por lo que no es necesario hacer referencias cruzadas y, en lugar de almacenar información en una tabla, se almacena en un documento. Si bien esto es muy similar a un almacén de clave-valor y, a veces, puede considerarse bajo su paraguas, la diferencia es que el NoSQL basado en documentos generalmente tiene alguna forma de codificación, como XML.
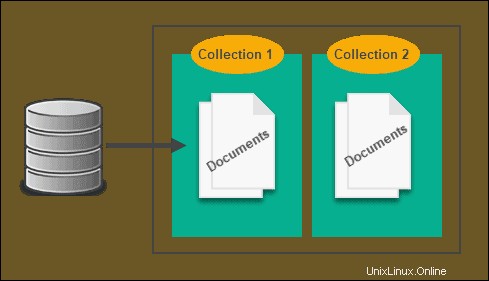
Hay una base de datos NoSQL específica de XML que utiliza un almacén de documentos. De hecho, Strider CD utiliza MongoDB como almacén de respaldo.
Tienda basada en columnas
Este tipo de modelo de datos almacena información en columnas, en lugar de filas, lo que es más habitual en SQL. Los datos se almacenan en columnas, que se agrupan en familias, y estas familias se agrupan en más columnas. Básicamente, esto crea un modelo de datos anidado de columnas casi ilimitado.
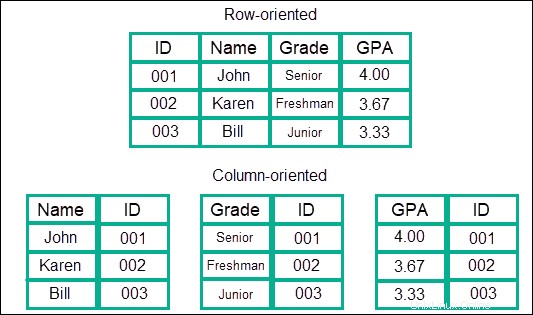
El beneficio es que ofrece velocidades increíblemente rápidas en comparación con otros modelos o NoSQL cuando se trata de búsquedas. Los datos se tratan como una entrada continua y, por lo tanto, no hay necesidad de saltar entre filas o diferentes áreas donde se almacena la información.
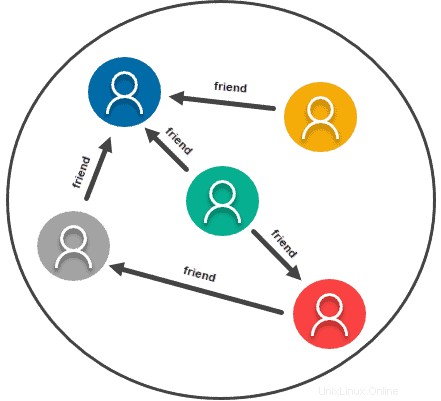
Almacenamiento basado en gráficos
Los modelos de datos gráficos o de red esencialmente tratan la relación entre dos piezas de información como si fueran tan importantes como la información misma. Como tal, este tipo de modelo de datos realmente está hecho para cualquier información que normalmente representarías en un gráfico. Utiliza relaciones y nodos, siendo los datos la información misma, y la relación se forma entre nodos.
¿Cómo se almacenan los datos en NoSQL?
El almacenamiento de datos NoSQL depende del tipo de base de datos que utilice. Dado que NoSQL no requiere un esquema, no existe un plan sobre cómo se deben almacenar los datos y, por lo tanto, varía entre las bases de datos.
En general, hay dos formas en que funciona el almacenamiento de datos NoSQL:
- En el disco usando B-Trees , con la parte superior permanentemente en RAM.
- En memoria donde todo está en RAM usando RB-Trees y cualquier cosa almacenada en el disco es solo un anexo.
Diseño de esquema para NoSQL
Dado que las bases de datos NoSQL realmente no tienen una estructura establecida, el desarrollo y el diseño del esquema tienden a centrarse en el modelo de datos físicos. Eso significa desarrollar para entornos grandes y expansivos horizontalmente, algo en lo que NoSQL sobresale. Por lo tanto, las peculiaridades y los problemas específicos que conlleva la escalabilidad están a la vanguardia.
Como tal, el primer paso es definir los requisitos comerciales, ya que la optimización del acceso a los datos es imprescindible y solo se puede lograr sabiendo lo que la empresa quiere. que ver con los datos. El diseño de su esquema debe complementar los flujos de trabajo vinculados a su caso de uso.
Hay varias formas de seleccionar la clave principal y, en última instancia, eso depende de los propios usuarios. Dicho esto, algunos datos podrían sugerir un esquema más eficiente, especialmente en términos de la frecuencia con la que se consultan esos datos.
Técnicas de modelado de datos NoSQL
Todas las técnicas de modelado de datos NoSQL se agrupan en tres grupos principales:
- Técnicas conceptuales
- Técnicas generales de modelado
- Técnicas de modelado de jerarquías
A continuación, analizaremos brevemente todas las técnicas de modelado de datos NoSQL.
Técnicas Conceptuales
Existen tres técnicas conceptuales para el modelado de datos NoSQL:
- Desnormalización . La desnormalización es una técnica bastante común y consiste en copiar los datos en varias tablas o formularios para simplificarlos. Con la desnormalización, agrupe fácilmente todos los datos que deben consultarse en un solo lugar. Por supuesto, esto significa que el volumen de datos aumenta para diferentes parámetros, lo que aumenta considerablemente el volumen de datos.
- Agregados . Esto permite a los usuarios formar entidades anidadas con estructuras internas complejas, así como variar su estructura particular. En última instancia, la agregación reduce las uniones al minimizar las relaciones uno a uno.
La mayoría de los modelos de datos NoSQL tienen alguna forma de esta técnica de esquema suave. Por ejemplo, las bases de datos de almacenamiento de gráficos y valores clave tienen valores que pueden tener cualquier formato, ya que esos modelos de datos no imponen restricciones al valor. De manera similar, otro ejemplo como BigTable tiene agregación a través de columnas y familias de columnas. - Uniones del lado de la aplicación. NoSQL generalmente no admite uniones, ya que las bases de datos NoSQL están orientadas a preguntas donde las uniones se realizan durante el tiempo de diseño. Esto se compara con las bases de datos relacionales donde se realizan en el momento de la ejecución de la consulta. Por supuesto, esto tiende a resultar en una penalización de rendimiento y, a veces, es inevitable.
Técnicas generales de modelado
Existen cinco técnicas generales para el modelado de datos NoSQL:
- Claves enumerables . En su mayor parte, los valores de clave no ordenados son muy útiles, ya que las entradas se pueden particionar en varios servidores dedicados con solo codificar la clave. Aun así, es útil agregar alguna forma de funcionalidad de clasificación a través de claves ordenadas, aunque puede agregar un poco más de complejidad y un impacto en el rendimiento.
- Reducción de dimensionalidad . Los sistemas de información geográfica suelen utilizar R-Tree índices y deben actualizarse en el lugar, lo que puede ser costoso si se trata de grandes volúmenes de datos. Otro enfoque tradicional es aplanar la estructura 2D en una lista simple, como lo que se hace con Geohash.
Con la reducción de dimensionalidad, puede asignar datos multidimensionales a un valor-clave simple o incluso a modelos no multidimensionales.
Utilice la reducción de dimensionalidad para asignar datos multidimensionales a un modelo de valor-clave o a otro modelo no multidimensional. - Tabla de índice. Con una tabla de índices, aproveche los índices en las tiendas que no necesariamente los admiten internamente. Intente crear y luego mantener una tabla única con claves que sigan un patrón de acceso específico. Por ejemplo, una tabla maestra para almacenar cuentas de usuario para acceder por ID de usuario.
- Índice de clave compuesta . Si bien es una técnica algo genérica, las claves compuestas son increíblemente útiles cuando se utilizan claves ordenadas. Si lo toma y lo combina con claves secundarias, puede crear un índice multidimensional que es bastante similar a la técnica de reducción de dimensionalidad mencionada anteriormente.
- Búsqueda invertida:agregación directa. El concepto detrás de esta técnica es usar un índice que cumpla con un conjunto específico de criterios, pero luego agregar esos datos con escaneos completos o alguna forma de representación original.
Este es más un patrón de procesamiento de datos que un modelo de datos, sin embargo, los modelos de datos ciertamente se ven afectados por el uso de este tipo de patrón de procesamiento. Tenga en cuenta que la recuperación aleatoria de los registros necesarios para esta técnica es ineficiente. Utilice el procesamiento de consultas en lotes para mitigar este problema.
Técnicas de modelado de jerarquías
Hay siete técnicas de modelado de jerarquía para datos NoSQL:
- Agregación de árboles. La agregación de árboles consiste esencialmente en modelar datos como un solo documento. Esto puede ser realmente eficiente cuando se trata de cualquier registro al que siempre se acceda a la vez, como un hilo de Twitter o una publicación de Reddit. Por supuesto, el problema es que el acceso aleatorio a cualquier entrada individual es ineficiente.
- Listas de adyacencia. Esta es una técnica sencilla en la que los nodos se modelan como registros independientes de matrices con antepasados directos. Esa es una forma complicada de decir que le permite buscar nodos por sus padres o hijos. Sin embargo, al igual que la agregación de árboles, también es bastante ineficiente para recuperar un subárbol completo para cualquier nodo dado.
- Caminos materializados. Esta técnica es una especie de desnormalización y se utiliza para evitar recorridos recursivos en estructuras de árbol. Principalmente, queremos atribuir los padres o hijos a cada nodo, lo que nos ayuda a determinar los predecesores o descendientes del nodo sin preocuparnos por el recorrido. Por cierto, podemos almacenar rutas materializadas como ID, ya sea como un conjunto o como una sola cadena.
- Conjuntos anidados . Una técnica estándar para estructuras en forma de árbol en bases de datos relacionales, es igualmente aplicable a NoSQL y bases de datos de documentos o clave-valor. El objetivo es almacenar las hojas del árbol como una matriz y luego asignar cada nodo que no sea una hoja a un rango de hojas usando índices de inicio/fin.
Modelarlo de esta manera es una forma eficiente de manejar datos inmutables, ya que solo requiere una pequeña cantidad de memoria y no necesariamente tiene que usar cruces. Dicho esto, las actualizaciones son costosas porque requieren actualizaciones de índices. - Acoplamiento de documentos anidados:nombres de campos numerados. La mayoría de los motores de búsqueda tienden a trabajar con documentos que son una lista plana de campos y valores, en lugar de algo con una estructura interna compleja. Como tal, esta técnica de modelado de datos intenta mapear estas estructuras complejas en un documento simple, por ejemplo, mapeando documentos con una estructura jerárquica, una dificultad común que puede encontrar.
Por supuesto, este tipo de trabajo es laborioso y no es fácilmente escalable, especialmente a medida que aumentan las estructuras anidadas. - Aplanamiento de documentos anidados:Consultas de proximidad. Una forma de resolver los problemas potenciales con la técnica de modelado de datos de Nombres de campos numerados es usar una técnica similar llamada Consultas de proximidad. Estos limitan la distancia entre las palabras en un documento, lo que ayuda a aumentar el rendimiento y disminuir el impacto de la velocidad de consulta.
- Procesamiento de gráficos por lotes. El procesamiento de gráficos por lotes es una gran técnica para explorar las relaciones ascendentes o descendentes de un nodo, en unos pocos pasos. Es un proceso costoso y no necesariamente escala muy bien. Mediante el uso de Message Passing y MapReduce podemos llevar a cabo este tipo de procesamiento de gráficos.