¿Qué es un sistema de archivos? Según el autor y colaborador de Linux Robert Love, "un sistema de archivos es un almacenamiento jerárquico de datos que se adhieren a una estructura específica". Sin embargo, esta descripción se aplica igualmente a VFAT (Tabla de asignación de archivos virtuales), Git y Cassandra (una base de datos NoSQL). Entonces, ¿qué distingue a un sistema de archivos?
Conceptos básicos del sistema de archivos
El kernel de Linux requiere que para que una entidad sea un sistema de archivos, también debe implementar open() , leer() y escribir() métodos en objetos persistentes que tienen nombres asociados con ellos. Desde el punto de vista de la programación orientada a objetos, el núcleo trata el sistema de archivos genérico como una interfaz abstracta, y estas tres funciones principales son "virtuales", sin una definición predeterminada. En consecuencia, la implementación del sistema de archivos predeterminado del kernel se denomina sistema de archivos virtual (VFS).
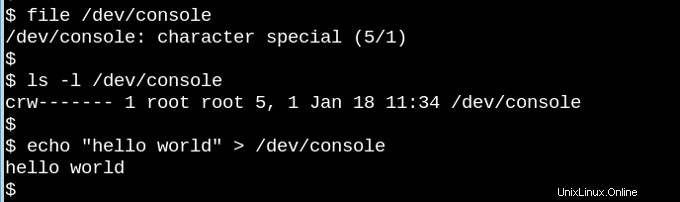
VFS subyace en la famosa observación de que en los sistemas tipo Unix "todo es un archivo". Considere lo extraño que es que la pequeña demostración anterior presenta el dispositivo de personaje /dev/console en realidad funciona La imagen muestra una sesión de Bash interactiva en un teletipo virtual (tty). Enviar una cadena al dispositivo de la consola virtual hace que aparezca en la pantalla virtual. VFS tiene otras propiedades, incluso más extrañas. Por ejemplo, es posible buscar en ellos.
Más recursos de Linux
- Hoja de trucos de los comandos de Linux
- Hoja de trucos de comandos avanzados de Linux
- Curso en línea gratuito:Descripción general técnica de RHEL
- Hoja de trucos de red de Linux
- Hoja de trucos de SELinux
- Hoja de trucos de los comandos comunes de Linux
- ¿Qué son los contenedores de Linux?
- Nuestros últimos artículos sobre Linux
Los sistemas de archivos familiares como ext4, NFS y /proc proporcionan definiciones de las tres funciones principales en una estructura de datos en lenguaje C llamada file_operations. Además, los sistemas de archivos particulares amplían y anulan las funciones de VFS en la forma familiar orientada a objetos. Como señala Robert Love, la abstracción de VFS permite a los usuarios de Linux copiar alegremente archivos hacia y desde sistemas operativos extranjeros o entidades abstractas como tuberías sin preocuparse por su formato de datos interno. En nombre del espacio de usuario, a través de una llamada al sistema, un proceso puede copiar desde un archivo a las estructuras de datos del kernel con el método read() de un sistema de archivos y luego usar el método write() de otro tipo de sistema de archivos para generar los datos.
Las definiciones de funciones que pertenecen al tipo base de VFS se encuentran en los archivos fs/*.c en el código fuente del kernel, mientras que los subdirectorios de fs/ contienen los sistemas de archivos específicos. El kernel también contiene entidades similares a sistemas de archivos, como cgroups, /dev y tmpfs, que se necesitan al principio del proceso de arranque y, por lo tanto, se definen en el subdirectorio init/ del kernel. Tenga en cuenta que cgroups, /dev y tmpfs no llaman a las tres funciones principales de file_operations, sino que leen y escriben directamente en la memoria.
El siguiente diagrama ilustra aproximadamente cómo el espacio de usuario accede a varios tipos de sistemas de archivos comúnmente montados en sistemas Linux. No se muestran construcciones como pipes, dmesg y POSIX clocks que también implementan struct file_operations y cuyos accesos, por lo tanto, pasan a través de la capa VFS.
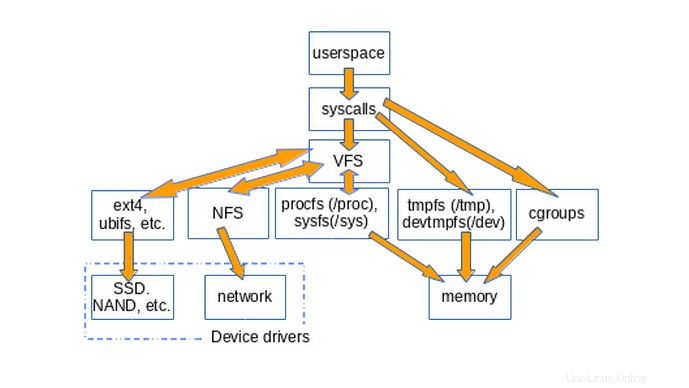
La existencia de VFS promueve la reutilización del código, ya que los métodos básicos asociados con los sistemas de archivos no necesitan ser reimplementados por cada tipo de sistema de archivos. ¡La reutilización de código es una práctica recomendada de ingeniería de software ampliamente aceptada! Por desgracia, si el código reutilizado presenta errores graves, todas las implementaciones que heredan los métodos comunes los padecen.
/tmp:Un consejo simple
Una manera fácil de averiguar qué VFS están presentes en un sistema es escribir mount | grep -v sd | grep -v :/ , que enumerará todos los sistemas de archivos montados que no residen en un disco y no son NFS en la mayoría de las computadoras. Uno de los montajes de VFS enumerados seguramente será /tmp, ¿verdad?

¿Por qué es desaconsejable mantener /tmp en el almacenamiento? Porque los archivos en /tmp son temporales (!), y los dispositivos de almacenamiento son más lentos que la memoria, donde se crean tmpfs. Además, los dispositivos físicos están más sujetos al desgaste por la escritura frecuente que la memoria. Por último, los archivos en /tmp pueden contener información confidencial, por lo que hacer que desaparezcan en cada reinicio es una función.
Desafortunadamente, los scripts de instalación para algunas distribuciones de Linux todavía crean /tmp en un dispositivo de almacenamiento de forma predeterminada. No se desespere si este es el caso de su sistema. Siga las sencillas instrucciones del siempre excelente Arch Wiki para solucionar el problema, teniendo en cuenta que la memoria asignada a tmpfs no está disponible para otros fines. En otras palabras, un sistema con un tmpfs gigante con archivos de gran tamaño puede quedarse sin memoria y fallar. Otro consejo:al editar el archivo /etc/fstab, asegúrese de terminarlo con una nueva línea, ya que de lo contrario su sistema no se iniciará. (Adivina cómo lo sé.)
/proc y /sys
Además de /tmp, los VFS con los que la mayoría de los usuarios de Linux están más familiarizados son /proc y /sys. (/dev se basa en la memoria compartida y no tiene operaciones de archivo). ¿Por qué dos sabores? Echemos un vistazo con más detalle.
El procfs ofrece una instantánea del estado instantáneo del kernel y los procesos que controla para el espacio de usuario. En /proc, el núcleo publica información sobre las funciones que proporciona, como interrupciones, memoria virtual y el programador. Además, /proc/sys es donde el espacio de usuario puede acceder a las configuraciones que se pueden configurar a través del comando sysctl. El estado y las estadísticas de los procesos individuales se informan en los directorios /proc/
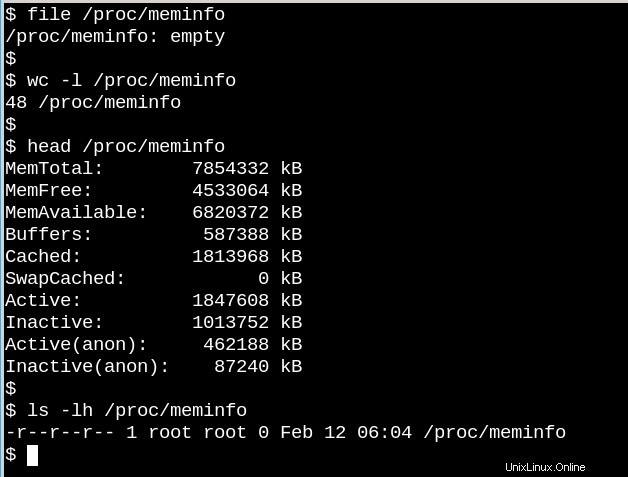
El comportamiento de los archivos /proc ilustra lo diferentes que pueden ser los sistemas de archivos en disco VFS. Por un lado, /proc/meminfo contiene la información que presenta el comando free . Por otro lado, ¡también está vacío! ¿Cómo puede ser esto? La situación recuerda a un famoso artículo escrito por el físico N. David Mermin de la Universidad de Cornell en 1985 llamado "¿Está la luna allí cuando nadie mira? La realidad y la teoría cuántica". La verdad es que el núcleo recopila estadísticas sobre la memoria cuando un proceso las solicita desde /proc, y en realidad hay nada en los archivos en /proc cuando nadie está mirando. Como dijo Mermin, "es una doctrina cuántica fundamental que una medida, en general, no revela un valor preexistente de la propiedad medida". (La respuesta a la pregunta sobre la luna se deja como ejercicio.)

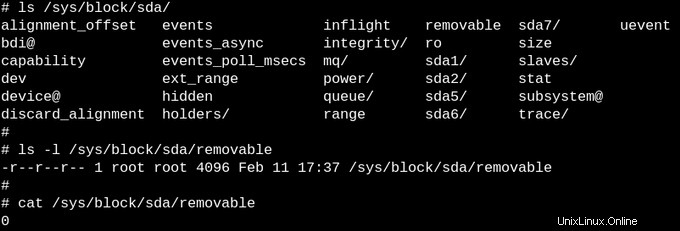
El aparente vacío de procfs tiene sentido, ya que la información disponible allí es dinámica. La situación con sysfs es diferente. Comparemos cuántos archivos de al menos un byte de tamaño hay en /proc versus /sys.
Procfs tiene precisamente uno, a saber, la configuración del kernel exportado, que es una excepción ya que solo debe generarse una vez por arranque. Por otro lado, /sys tiene muchos archivos más grandes, la mayoría de los cuales comprenden una página de memoria. Por lo general, los archivos sysfs contienen exactamente un número o cadena, en contraste con las tablas de información producidas al leer archivos como /proc/meminfo.
El propósito de sysfs es exponer las propiedades de lectura y escritura de lo que el núcleo llama "kobjects" al espacio de usuario. El único propósito de kobjects es el recuento de referencias:cuando se elimina la última referencia a un kobject, el sistema reclamará los recursos asociados con él. Sin embargo, /sys constituye la mayor parte del famoso "ABI estable para el espacio de usuario" del kernel que nadie, bajo ninguna circunstancia, puede "romper". Eso no significa que los archivos en sysfs sean estáticos, lo que sería contrario al recuento de referencias de objetos volátiles.
En cambio, la ABI estable del kernel restringe lo que puede aparecen en /sys, no lo que realmente está presente en un instante dado. Enumerar los permisos en archivos en sysfs da una idea de cómo se pueden establecer o leer los parámetros configurables y ajustables de dispositivos, módulos, sistemas de archivos, etc. La lógica obliga a la conclusión de que procfs también forma parte de la ABI estable del kernel, aunque la documentación del kernel no lo establece de manera tan explícita.
Fisgonear en VFS con herramientas eBPF y bcc
La forma más fácil de aprender cómo el kernel administra los archivos sysfs es verlo en acción, y la forma más sencilla de verlo en ARM64 o x86_64 es usar eBPF. eBPF (filtro de paquetes de Berkeley extendido) consiste en una máquina virtual que se ejecuta dentro del kernel que los usuarios privilegiados pueden consultar desde la línea de comandos. La fuente del kernel le dice al lector lo que el kernel puede hacer; la ejecución de herramientas eBPF en un sistema arrancado muestra en cambio lo que el núcleo realmente hace .
Afortunadamente, comenzar con eBPF es bastante fácil a través de las herramientas bcc, que están disponibles como paquetes de las principales distribuciones de Linux y han sido ampliamente documentadas por Brendan Gregg. Las herramientas bcc son secuencias de comandos de Python con pequeños fragmentos de C incrustados, lo que significa que cualquiera que se sienta cómodo con cualquiera de los dos idiomas puede modificarlos fácilmente. En este recuento, hay 80 secuencias de comandos de Python en bcc/tools, por lo que es muy probable que un administrador de sistemas o desarrollador encuentre una existente relevante para sus necesidades.
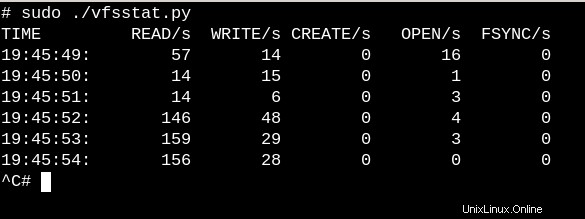
Para tener una idea muy aproximada sobre el trabajo que realizan los VFS en un sistema en ejecución, pruebe el simple vfscount o vfsstat, que muestran que cada segundo se producen docenas de llamadas a vfs_open() y sus amigos.
Para un ejemplo menos trivial, veamos qué sucede en sysfs cuando se inserta una memoria USB en un sistema en ejecución.
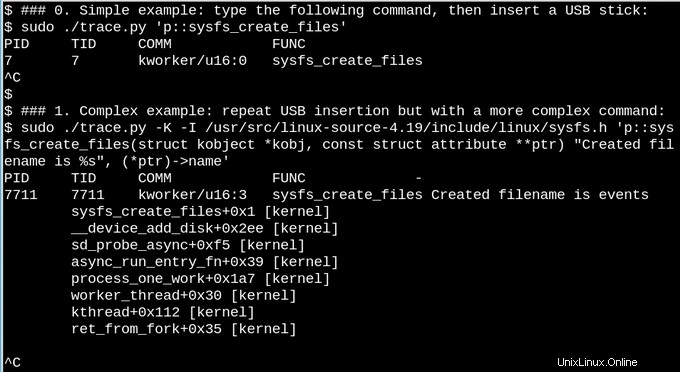
En el primer ejemplo simple anterior, el script de herramientas trace.py bcc imprime un mensaje cada vez que se ejecuta el comando sysfs_create_files(). Vemos que sysfs_create_files() fue iniciado por un subproceso de kworker en respuesta a la inserción de la memoria USB, pero ¿qué archivo se creó? El segundo ejemplo ilustra todo el poder de eBPF. Aquí, trace.py está imprimiendo la traza inversa del núcleo (opción -K) más el nombre del archivo creado por sysfs_create_files(). El fragmento dentro de las comillas simples es un código fuente C, que incluye una cadena de formato fácilmente reconocible, que el script de Python proporcionado induce a un compilador LLVM justo a tiempo para compilar y ejecutar dentro de una máquina virtual en el kernel. La firma completa de la función sysfs_create_files() debe reproducirse en el segundo comando para que la cadena de formato pueda hacer referencia a uno de los parámetros. Cometer errores en este fragmento de C da como resultado errores reconocibles del compilador de C. Por ejemplo, si -I se omite el parámetro, el resultado es "Error al compilar el texto BPF". Los desarrolladores que están familiarizados con C o Python encontrarán que las herramientas de BCC son fáciles de ampliar y modificar.
Cuando se inserta la memoria USB, aparece el seguimiento del kernel que muestra que PID 7711 es un subproceso de kworker que creó un archivo llamado "eventos" en sysfs. Una invocación correspondiente con sysfs_remove_files() muestra que la eliminación de la memoria USB da como resultado la eliminación del archivo de eventos, de acuerdo con la idea del recuento de referencias. Ver sysfs_create_link() con eBPF durante la inserción de la memoria USB (no se muestra) revela que se crean no menos de 48 enlaces simbólicos.
¿Cuál es el propósito del archivo de eventos de todos modos? El uso de cscope para encontrar la función __device_add_disk() revela que llama a disk_add_events(), y se puede escribir "media_change" o "eject_request" en el archivo de eventos. Aquí, la capa de bloques del kernel informa al espacio de usuario sobre la aparición y desaparición del "disco". Considere qué tan informativo es este método de investigar cómo funciona la inserción de una memoria USB en comparación con tratar de descubrir el proceso únicamente desde la fuente.
Los sistemas de archivos raíz de solo lectura hacen posibles los dispositivos integrados
Sin duda, nadie apaga un servidor o un sistema de escritorio desconectando el enchufe de alimentación. ¿Por qué? Debido a que los sistemas de archivos montados en los dispositivos de almacenamiento físico pueden tener escrituras pendientes, y las estructuras de datos que registran su estado pueden perder la sincronización con lo que está escrito en el almacenamiento. Cuando eso suceda, los propietarios del sistema tendrán que esperar en el siguiente arranque a que se ejecute la herramienta de recuperación del sistema de archivos fsck y, en el peor de los casos, perderán datos.
Sin embargo, los aficionados habrán oído que muchos dispositivos IoT e integrados como enrutadores, termostatos y automóviles ahora ejecutan Linux. Muchos de estos dispositivos carecen casi por completo de una interfaz de usuario, y no hay forma de "desarrancarlos" limpiamente. Considere la posibilidad de poner en marcha un automóvil con una batería agotada donde la energía de la unidad principal que ejecuta Linux sube y baja repetidamente. ¿Cómo es que el sistema arranca sin un fsck largo cuando el motor finalmente comienza a funcionar? La respuesta es que los dispositivos integrados se basan en un sistema de archivos raíz de solo lectura (ro-rootfs para abreviar).
Un ro-rootfs ofrece muchas ventajas que son menos obvias que la incorruptibilidad. Una es que el malware no puede escribir en /usr o /lib si ningún proceso de Linux puede escribir allí. Otra es que un sistema de archivos en gran medida inmutable es fundamental para el soporte de campo de dispositivos remotos, ya que el personal de soporte posee sistemas locales que son nominalmente idénticos a los que están en el campo. Quizás la ventaja más importante (pero también la más sutil) es que ro-rootfs obliga a los desarrolladores a decidir durante la fase de diseño de un proyecto qué objetos del sistema serán inmutables. Tratar con ro-rootfs a menudo puede ser inconveniente o incluso doloroso, como suelen ser las variables const en los lenguajes de programación, pero los beneficios compensan fácilmente los gastos generales adicionales.
La creación de un rootfs de solo lectura requiere una cantidad adicional de esfuerzo para los desarrolladores integrados, y ahí es donde entra en juego VFS. Linux necesita archivos en /var para poder escribir y, además, muchas aplicaciones populares que ejecutan los sistemas integrados intentarán crear una configuración. archivos de puntos en $HOME. Una solución para los archivos de configuración en el directorio de inicio suele ser generarlos previamente y construirlos en rootfs. Para /var, un enfoque es montarlo en una partición grabable separada mientras que / se monta como de solo lectura. El uso de montajes de unión o superposición es otra alternativa popular.
Monturas de enlace y superposición y su uso en contenedores
Correr montura de hombre es el mejor lugar para obtener información sobre los montajes de enlace y superposición, que brindan a los desarrolladores integrados y administradores de sistemas el poder de crear un sistema de archivos en una ubicación de ruta y luego proporcionarlo a las aplicaciones en una segunda. Para los sistemas integrados, la implicación es que es posible almacenar los archivos en /var en un dispositivo flash que no se puede escribir, pero superponer o unir una ruta en un tmpfs en la ruta /var en el arranque para que las aplicaciones puedan garabatear allí a su corazón. deleitar. En el próximo encendido, los cambios en /var desaparecerán. Los montajes superpuestos proporcionan una unión entre tmpfs y el sistema de archivos subyacente y permiten la modificación aparente de un archivo existente en un ro-rootfs, mientras que los montajes de enlace pueden hacer que los nuevos directorios tmpfs vacíos se muestren como grabables en las rutas de ro-rootfs. Si bien overlayfs es un tipo de sistema de archivos adecuado, la función de espacio de nombres VFS implementa los montajes de enlace.
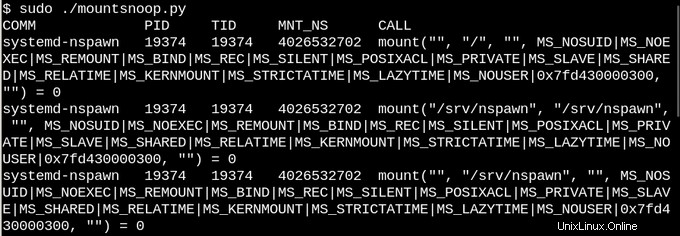
Según la descripción de los montajes overlay y bind, nadie se sorprenderá de que los contenedores de Linux hagan un uso intensivo de ellos. Espíemos lo que sucede cuando empleamos systemd-nspawn para iniciar un contenedor ejecutando la herramienta mountsnoop de bcc:

Y veamos qué pasó:
Aquí, systemd-nspawn proporciona archivos seleccionados en procfs y sysfs del host al contenedor en las rutas en sus rootfs. Además del indicador MS_BIND que establece el montaje de enlace, algunos de los otros indicadores que invoca la llamada del sistema "mount" determinan la relación entre los cambios en el espacio de nombres del host y en el contenedor. Por ejemplo, el montaje de vinculación puede propagar cambios en /proc y /sys al contenedor u ocultarlos, según la invocación.
Resumen
Comprender las funciones internas de Linux puede parecer una tarea imposible, ya que el kernel en sí contiene una cantidad gigantesca de código, dejando de lado las aplicaciones del espacio de usuario de Linux y la interfaz de llamada al sistema en las bibliotecas C como glibc. Una forma de progresar es leer el código fuente de un subsistema del kernel con énfasis en la comprensión de las llamadas y los encabezados del sistema orientados al espacio de usuario, además de las principales interfaces internas del kernel, ejemplificadas aquí por la tabla file_operations. Las operaciones de archivo son lo que hace que "todo es un archivo" realmente funcione, por lo que manejarlas es particularmente satisfactorio. Los archivos fuente del kernel C en el directorio fs/ de nivel superior constituyen su implementación de sistemas de archivos virtuales, que son la capa shim que permite una interoperabilidad amplia y relativamente sencilla de sistemas de archivos y dispositivos de almacenamiento populares. Los montajes de enlace y superposición a través de espacios de nombres de Linux son la magia de VFS que hace posibles los contenedores y los sistemas de archivos raíz de solo lectura. En combinación con un estudio del código fuente, la función del kernel eBPF y su interfaz bcc hacen que probar el kernel sea más simple que nunca.
Muchas gracias a Akkana Peck y Michael Eager por sus comentarios y correcciones.
Alison Chaiken presentará los sistemas de archivos virtuales:por qué los necesitamos y cómo funcionan en la 17.ª Exposición Linux del Sur de California (SCaLE 17x) del 7 al 10 de marzo en Pasadena, California.