AWK es un poderoso lenguaje de programación basado en datos cuyo origen se remonta a los primeros días de Unix. Inicialmente se desarrolló para escribir programas de una sola línea, pero desde entonces ha evolucionado hasta convertirse en un lenguaje de programación completo. AWK recibe su nombre de las iniciales de sus autores:Aho, Weinberger y Kernighan. El comando awk en Linux y otros sistemas Unix invoca al intérprete que ejecuta los scripts AWK. Existen varias implementaciones de awk en sistemas recientes, como gawk (GNU awk), mawk (Minimal awk) y nawk (New awk), entre otros. Consulte los siguientes ejemplos si desea dominar awk.
Comprensión de los programas AWK
Los programas escritos en awk consisten en reglas, que son simplemente un par de patrones y acciones. Los patrones se agrupan dentro de una llave {}, y la parte de acción se activa cada vez que awk encuentra textos que coinciden con el patrón. Aunque awk fue desarrollado para escribir frases ingeniosas, los usuarios experimentados pueden escribir fácilmente scripts complejos con él.
Los programas AWK son muy útiles para el procesamiento de archivos a gran escala. Identifica campos de texto utilizando caracteres especiales y separadores. También ofrece construcciones de programación de alto nivel como matrices y bucles. Por lo tanto, escribir programas robustos utilizando awk simple es muy factible.
Ejemplos prácticos del comando awk en Linux
Los administradores normalmente usan awk para la extracción de datos y la generación de informes junto con otros tipos de manipulación de archivos. A continuación, hemos discutido awk con más detalle. Siga los comandos cuidadosamente y pruébelos en su terminal para una comprensión completa.
1. Imprimir campos específicos desde la salida de texto
Los comandos de Linux más utilizados muestran su salida usando varios campos. Normalmente, usamos el comando de corte de Linux para extraer un campo específico de dichos datos. Sin embargo, el siguiente comando le muestra cómo hacer esto usando el comando awk.
$ who | awk '{print $1}' Este comando mostrará solo el primer campo de la salida del comando who. Entonces, simplemente obtendrá los nombres de usuario de todos los usuarios registrados actualmente. Toma, $1 representa el primer campo. Necesitas usar $N si desea extraer el campo N-th.
2. Imprimir varios campos desde la salida de texto
- - El intérprete awk nos permite imprimir cualquier número de campos que queramos. Los siguientes ejemplos nos muestran cómo extraer los primeros dos campos de la salida del comando who.
$ who | awk '{print $1, $2}' También puede controlar el orden de los campos de salida. El siguiente ejemplo muestra primero la segunda columna producida por el comando who y luego la primera columna en el segundo campo.
$ who | awk '{print $2, $1}' Simplemente omita los parámetros del campo ($N ) para mostrar todos los datos.
3. Usar instrucciones BEGIN
La declaración BEGIN permite a los usuarios imprimir alguna información conocida en la salida. Por lo general, se usa para formatear los datos de salida generados por awk. La sintaxis de esta declaración se muestra a continuación.
BEGIN { Actions}
{ACTION} Las acciones que forman la sección BEGIN siempre se activan. Luego, awk lee las líneas restantes una por una y ve si es necesario hacer algo.
$ who | awk 'BEGIN {print "User\tFrom"} {print $1, $2}' El comando anterior etiquetará los dos campos de salida extraídos de la salida del comando who.
4. Usar declaraciones END
También puede usar la declaración END para asegurarse de que ciertas acciones siempre se realicen al final de su operación. Simplemente coloque la sección FIN después del conjunto principal de acciones.
$ who | awk 'BEGIN {print "User\tFrom"} {print $1, $2} END {print "--COMPLETED--"}' El comando anterior agregará la cadena dada al final de la salida.
5. Buscar usando patrones
Una gran parte del funcionamiento de awk implica la coincidencia de patrones y expresiones regulares. Como ya hemos discutido, awk busca patrones en cada línea de entrada y solo ejecuta la acción cuando se activa una coincidencia. Nuestras reglas anteriores consistían únicamente en acciones. A continuación, ilustramos los conceptos básicos de la coincidencia de patrones usando el comando awk en Linux.
$ who | awk '/mary/ {print}' Este comando verá si el usuario mary está actualmente conectado o no. Mostrará la línea completa si se encuentra alguna coincidencia.
6. Extraer información de archivos
El comando awk funciona muy bien con archivos y puede usarse para tareas complejas de procesamiento de archivos. El siguiente comando ilustra cómo awk maneja los archivos.
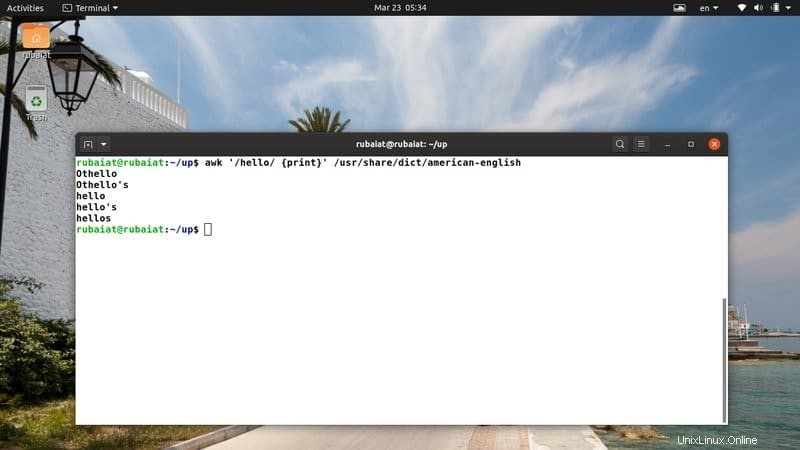
$ awk '/hello/ {print}' /usr/share/dict/american-english Este comando busca el patrón 'hola' en el archivo del diccionario americano-inglés. Está disponible en la mayoría de las distribuciones basadas en Linux. Por lo tanto, puede probar fácilmente programas awk en este archivo.
7. Lea el script AWK del archivo fuente
Aunque escribir programas de una sola línea es útil, también puede escribir programas grandes usando awk por completo. Deberá guardarlos y ejecutar su programa utilizando el archivo fuente.
$ awk -f script-file $ awk --file script-file
La -f o –archivo La opción nos permite especificar el archivo del programa. Sin embargo, no necesita usar comillas (‘ ‘) dentro del archivo de script ya que el shell de Linux no interpretará el código del programa de esta manera.
8. Establecer separador de campo de entrada
Un separador de campo es un delimitador que divide el registro de entrada. Podemos especificar fácilmente separadores de campo para awk usando -F o –separador de campo opción. Consulte los siguientes comandos para ver cómo funciona.
$ echo "This-is-a-simple-example" | awk -F - ' {print $1} '
$ echo "This-is-a-simple-example" | awk --field-separator - ' {print $1} ' Funciona igual cuando se usan archivos de script en lugar del comando awk de una sola línea en Linux.
9. Imprimir información basada en la condición
Hemos discutido el comando de corte de Linux en una guía anterior. Ahora le mostraremos cómo extraer información usando awk solo cuando se cumplen ciertos criterios. Usaremos el mismo archivo de prueba que usamos en esa guía. Así que dirígete allí y haz una copia del test.txt archivo.
$ awk '$4 > 50' test.txt
Este comando imprimirá todas las naciones del archivo test.txt, que tiene más de 50 millones de habitantes.
10. Imprimir información comparando expresiones regulares
El siguiente comando awk verifica si el tercer campo de cualquier línea contiene el patrón 'Lira' e imprime la línea completa si se encuentra una coincidencia. Nuevamente estamos usando el archivo test.txt que se usa para ilustrar el comando de corte de Linux. Así que asegúrese de tener este archivo antes de continuar.
$ awk '$3 ~ /Lira/' test.txt
Si lo desea, puede optar por imprimir solo una parte específica de cualquier coincidencia.
11. Cuente el número total de líneas en la entrada
El comando awk tiene muchas variables de propósito especial que nos permiten hacer muchas cosas avanzadas fácilmente. Una de esas variables es NR, que contiene el número de línea actual.
$ awk 'END {print NR} ' test.txt Este comando mostrará cuántas líneas hay en nuestro archivo test.txt. Primero itera sobre cada línea y, una vez que llega a END, imprime el valor de NR, que contiene el número total de líneas en este caso.
12. Establecer separador de campo de salida
Anteriormente, mostramos cómo seleccionar separadores de campos de entrada usando -F o –separador de campo opción. El comando awk también nos permite especificar el separador de campo de salida. El siguiente ejemplo demuestra esto usando un ejemplo práctico.
$ date | awk 'OFS="-" {print$2,$3,$6}' Este comando imprime la fecha actual usando el formato dd-mm-aa. Ejecute el programa de fecha sin awk para ver cómo se ve la salida predeterminada.
13. Uso de la construcción If
Al igual que otros lenguajes de programación populares, awk también proporciona a los usuarios las construcciones if-else. La declaración if en awk tiene la siguiente sintaxis.
if (expression)
{
first_action
second_action
} Las acciones correspondientes solo se realizan si la expresión condicional es verdadera. El siguiente ejemplo demuestra esto usando nuestro archivo de referencia test.txt .
$ awk '{ if ($4>100) print }' test.txt No es necesario que mantenga estrictamente la sangría.
14. Uso de construcciones If-Else
Puede construir escaleras if-else útiles utilizando la siguiente sintaxis. Son útiles cuando se diseñan scripts awk complejos que tratan con datos dinámicos.
if (expression) first_action else second_action
$ awk '{ if ($4>100) print; else print }' test.txt El comando anterior imprimirá el archivo de referencia completo ya que el cuarto campo no es mayor a 100 para cada línea.
15. Establecer el ancho del campo
A veces, los datos de entrada son bastante desordenados y a los usuarios les puede resultar difícil visualizarlos en sus informes. Afortunadamente, awk proporciona una poderosa variable incorporada llamada FIELDWIDTHS que nos permite definir una lista de anchos separados por espacios en blanco.
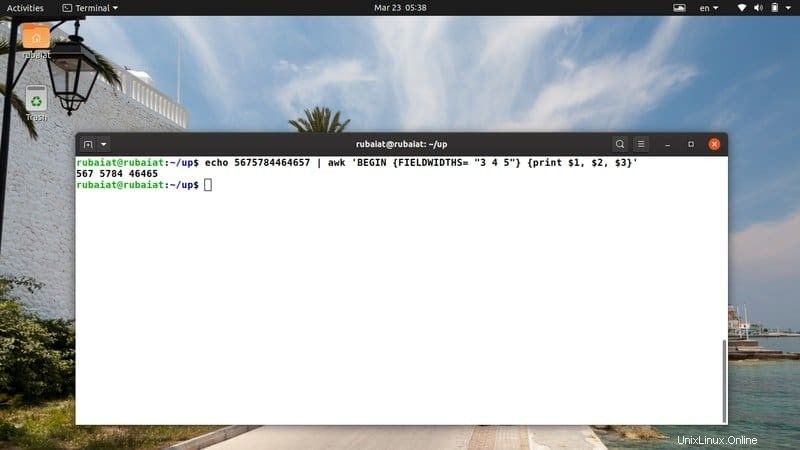
$ echo 5675784464657 | awk 'BEGIN {FIELDWIDTHS= "3 4 5"} {print $1, $2, $3}' Es muy útil al analizar datos dispersos ya que podemos controlar el ancho del campo de salida exactamente como queremos.
16. Establecer el separador de registros
El RS o Record Separator es otra variable incorporada que nos permite especificar cómo se separan los registros. Primero creemos un archivo que demuestre el funcionamiento de esta variable awk.
$ cat new.txt Melinda James 23 New Hampshire (222) 466-1234 Daniel James 99 Phonenix Road (322) 677-3412
$ awk 'BEGIN{FS="\n"; RS=""} {print $1,$3}' new.txt Este comando analizará el documento y mostrará el nombre y la dirección de las dos personas.
17. Variables de entorno de impresión
El comando awk en Linux nos permite imprimir variables de entorno fácilmente usando la variable ENVIRON. El siguiente comando demuestra cómo usar esto para imprimir el contenido de la variable PATH.
$ awk 'BEGIN{ print ENVIRON["PATH"] }' Puede imprimir el contenido de cualquier variable de entorno sustituyendo el argumento de la variable ENVIRON. El siguiente comando imprime el valor de la variable de entorno HOME.
$ awk 'BEGIN{ print ENVIRON["HOME"] }' 18. Omitir algunos campos de la salida
El comando awk nos permite omitir líneas específicas de nuestra salida. El siguiente comando demostrará esto usando nuestro archivo de referencia test.txt .
$ awk -F":" '{$2=""; print}' test.txt Este comando omitirá la segunda columna de nuestro archivo, que contiene el nombre de la capital de cada país. También puede omitir más de un campo, como se muestra en el siguiente comando.
$ awk -F":" '{$2="";$3="";print}' test.txt 19. Eliminar líneas vacías
A veces, los datos pueden contener demasiadas líneas en blanco. Puede usar el comando awk para eliminar líneas vacías con bastante facilidad. Consulte el siguiente comando para ver cómo funciona esto en la práctica.
$ awk '/^[ \t]*$/{next}{print}' new.txt Hemos eliminado todas las líneas vacías del archivo new.txt usando una expresión regular simple y un awk incorporado llamado next.
20. Eliminar espacios en blanco finales
La salida de muchos comandos de Linux contiene espacios en blanco al final. Podemos usar el comando awk en Linux para eliminar espacios en blanco como espacios y tabulaciones. Consulte el siguiente comando para ver cómo abordar estos problemas con awk.
$ awk '{sub(/[ \t]*$/, "");print}' new.txt test.txt Agregue algunos espacios en blanco finales a nuestros archivos de referencia y verifique si awk los eliminó con éxito o no. Hizo esto con éxito en mi máquina.
21. Verifique la cantidad de campos en cada línea
Podemos verificar fácilmente cuántos campos hay en una línea usando un simple awk one-liner. Hay muchas maneras de hacer esto, pero usaremos algunas de las variables integradas de awk para esta tarea. La variable NR nos da el número de línea y la variable NF nos da el número de campos.
$ awk '{print NR,"-->",NF}' test.txt Ahora podemos confirmar cuántos campos hay por línea en nuestro test.txt documento. Dado que cada línea de este archivo contiene 5 campos, estamos seguros de que el comando funciona como se esperaba.
22. Verificar nombre de archivo actual
La variable awk FILENAME se utiliza para verificar el nombre de archivo de entrada actual. Estamos demostrando cómo funciona esto usando un ejemplo simple. Sin embargo, puede ser útil en situaciones en las que el nombre del archivo no se conoce explícitamente o hay más de un archivo de entrada.
$ awk '{print FILENAME}' test.txt
$ awk '{print FILENAME}' test.txt new.txt Los comandos anteriores imprimen el nombre de archivo en el que está trabajando awk cada vez que procesa una nueva línea de los archivos de entrada.
23. Verificar número de registros procesados
El siguiente ejemplo mostrará cómo podemos verificar la cantidad de registros procesados por el comando awk. Dado que una gran cantidad de administradores de sistemas Linux utilizan awk para generar informes, es muy útil para ellos.
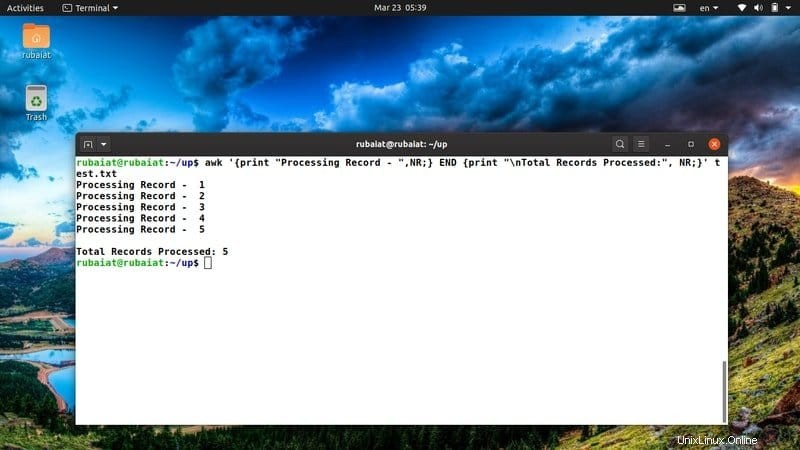
$ awk '{print "Processing Record - ",NR;} END {print "\nTotal Records Processed:", NR;}' test.txt A menudo uso este fragmento awk para tener una visión general clara de mis acciones. Puede modificarlo fácilmente para adaptarlo a nuevas ideas o acciones.
24. Imprimir el número total de caracteres en un registro
El lenguaje awk proporciona una función útil llamada length() que nos dice cuántos caracteres hay en un registro. Es muy útil en varios escenarios. Eche un vistazo rápido al siguiente ejemplo para ver cómo funciona.
$ echo "A random text string..." | awk '{ print length($0); }' $ awk '{ print length($0); }' /etc/passwd El comando anterior imprimirá el número total de caracteres presentes en cada línea de la cadena o archivo de entrada.
25. Imprimir todas las líneas más largas que una longitud especificada
Podemos agregar algunos condicionales al comando anterior y hacer que solo imprima aquellas líneas que son mayores que una longitud predefinida. Es útil cuando ya tiene una idea sobre la longitud de un registro específico.
$ echo "A random text string..." | awk 'length($0) > 10'
$ awk '{ length($0) > 5; }' /etc/passwd Puede agregar más opciones y/o argumentos para ajustar el comando según sus requisitos.
26. Imprima el número de líneas, caracteres y palabras
El siguiente comando awk en Linux imprime la cantidad de líneas, caracteres y palabras en una entrada dada. Utiliza la variable NR, así como algunas operaciones aritméticas básicas para realizar esta operación.
$ echo "This is a input line..." | awk '{ w += NF; c += length + 1 } END { print NR, w, c }' Muestra que hay 1 línea, 5 palabras y exactamente 24 caracteres presentes en la cadena de entrada.
27. Calcular la frecuencia de las palabras
Podemos combinar matrices asociativas y el ciclo for en awk para calcular la frecuencia de palabras de un documento. El siguiente comando puede parecer un poco complejo, pero es bastante simple una vez que comprende claramente las construcciones básicas.
$ awk 'BEGIN {FS="[^a-zA-Z]+" } { for (i=1; i<=NF; i++) words[tolower($i)]++ } END { for (i in words) print i, words[i] }' test.txt Si tiene problemas con el fragmento de código de una sola línea, copie el siguiente código en un nuevo archivo y ejecútelo usando la fuente.
$ cat > frequency.awk
BEGIN {
FS="[^a-zA-Z]+"
}
{
for (i=1; i<=NF; i++)
words[tolower($i)]++
}
END {
for (i in words)
print i, words[i]
} Luego ejecútelo usando -f opción.
$ awk -f frequency.awk test.txt
28. Renombrar archivos usando AWK
El comando awk se puede usar para cambiar el nombre de todos los archivos que coincidan con ciertos criterios. El siguiente comando ilustra cómo usar awk para cambiar el nombre de todos los archivos .MP3 en un directorio a archivos .mp3.
$ touch {a,b,c,d,e}.MP3
$ ls *.MP3 | awk '{ printf("mv \"%s\" \"%s\"\n", $0, tolower($0)) }'
$ ls *.MP3 | awk '{ printf("mv \"%s\" \"%s\"\n", $0, tolower($0)) }' | sh Primero, creamos algunos archivos de demostración con extensión .MP3. El segundo comando muestra al usuario lo que sucede cuando el cambio de nombre es exitoso. Finalmente, el último comando realiza la operación de cambio de nombre usando el comando mv en Linux.
29. Imprimir la raíz cuadrada de un número
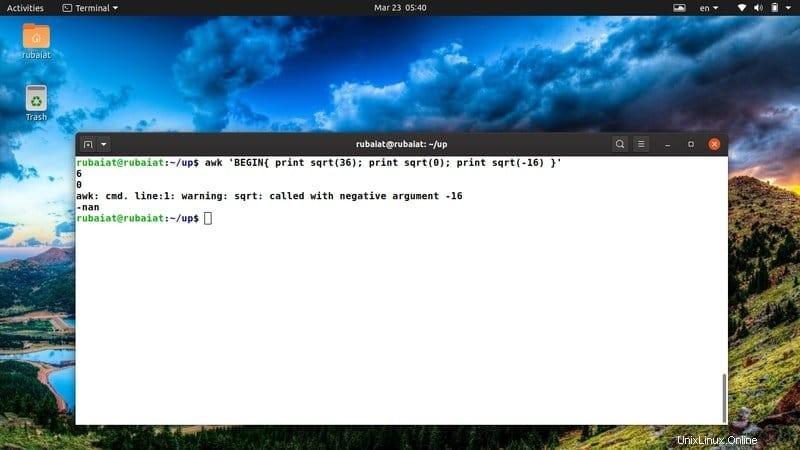
AWK ofrece varias funciones integradas para manipular números. Una de ellas es la función sqrt(). Es una función tipo C que devuelve la raíz cuadrada de un número dado. Eche un vistazo rápido al siguiente ejemplo para ver cómo funciona esto en general.
$ awk 'BEGIN{ print sqrt(36); print sqrt(0); print sqrt(-16) }' Como no puede determinar la raíz cuadrada de un número negativo, la salida mostrará una palabra clave especial llamada 'nan' en lugar de sqrt(-12).
30. Imprimir el logaritmo de un número
La función awk log() proporciona el logaritmo natural de un número. Sin embargo, solo funcionará con números positivos, así que tenga cuidado al validar la entrada de los usuarios. De lo contrario, alguien podría romper sus programas awk y obtener acceso sin privilegios a los recursos del sistema.
$ awk 'BEGIN{ print log(36); print log(0); print log(-16) }' Debería ver el logaritmo de 36 y verificar que el logaritmo de 0 es infinito, y el logaritmo de un valor negativo es "No es un número" o nan.
31. Imprimir el exponencial de un número
La exponencial de un número n proporciona el valor de e^n. Por lo general, se usa en scripts awk que manejan números grandes o lógica aritmética compleja. Podemos generar el exponencial de un número usando la función incorporada de awk exp().
$ awk 'BEGIN{ print exp(30); print log(0); print exp(-16) }' Sin embargo, awk no puede calcular exponencial para números extremadamente grandes. Debe hacer tales cálculos usando lenguajes de programación de bajo nivel como C y alimentar el valor a sus scripts awk.
32. Genera números aleatorios usando AWK
Podemos utilizar el comando awk en Linux para generar números aleatorios. Estos números estarán en el rango de 0 a 1, pero nunca 0 o 1. Puede multiplicar un valor fijo con el número resultante para obtener un valor aleatorio mayor.
$ awk 'BEGIN{ print rand(); print rand()*99 }' La función rand() no necesita ningún argumento. Además, los números generados por esta función no son precisamente aleatorios sino pseudoaleatorios. Además, es bastante fácil predecir estos números de una ejecución a otra. Por lo tanto, no debe confiar en ellos para cálculos sensibles.
33. Advertencias del compilador de color en rojo
Los compiladores modernos de Linux arrojarán advertencias si su código no mantiene los estándares del lenguaje o tiene errores que no detienen la ejecución del programa. El siguiente comando awk imprimirá las líneas de advertencia generadas por un compilador en rojo.
$ gcc -Wall main.c |& awk '/: warning:/{print "\x1B[01;31m" $0 "\x1B[m";next;}{print}' Este comando es útil si desea identificar específicamente las advertencias del compilador. Puede usar este comando con cualquier compilador que no sea gcc, solo asegúrese de cambiar el patrón /:advertencia:/ para reflejar ese compilador en particular.
34. Imprima la información UUID del sistema de archivos
El UUID o Universally Unique Identifier es un número que se puede usar para identificar recursos como el sistema de archivos de Linux. Simplemente podemos imprimir la información UUID de nuestro sistema de archivos usando el siguiente comando awk de Linux.
$ awk '/UUID/ {print $0}' /etc/fstab Este comando busca el UUID de texto en /etc/fstab archivo usando patrones awk. Devuelve un comentario del archivo que no nos interesa. El siguiente comando se asegurará de que solo obtengamos aquellas líneas que comienzan con UUID.
$ awk '/^UUID/ {print $1}' /etc/fstab Restringe la salida al primer campo. Así que solo obtenemos los números UUID.
35. Imprima la versión de la imagen del kernel de Linux
Varias distribuciones de Linux utilizan diferentes imágenes del kernel de Linux. Podemos imprimir fácilmente la imagen exacta del kernel en la que se basa nuestro sistema usando awk. Consulte el siguiente comando para ver cómo funciona esto en general.
$ uname -a | awk '{print $3}' Primero emitimos el comando uname con -a opción y luego canalizó estos datos a awk. Luego extrajimos la información de la versión de la imagen del kernel usando awk.
36. Agregar números de línea antes de las líneas
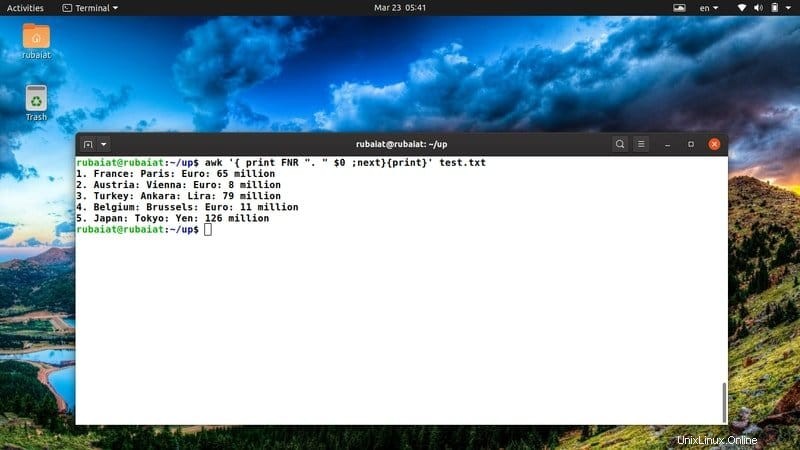
Los usuarios pueden encontrar archivos de texto que no contienen números de línea con bastante frecuencia. Afortunadamente, puede agregar fácilmente números de línea a un archivo usando el comando awk en Linux. Eche un vistazo de cerca al siguiente ejemplo para ver cómo funciona esto en la vida real.
$ awk '{ print FNR ". " $0 ;next}{print}' test.txt El comando anterior agregará un número de línea antes de cada una de las líneas en nuestro archivo de referencia test.txt. Utiliza la variable FNR integrada de awk para abordar esto.
37. Imprimir un archivo después de ordenar los contenidos
También podemos usar awk para imprimir una lista ordenada de todas las líneas. Los siguientes comandos imprimen el nombre de todos los países en nuestro test.txt en orden ordenado.
$ awk -F ':' '{ print $1 }' test.txt | sort El siguiente comando imprimirá el nombre de inicio de sesión de todos los usuarios desde /etc/passwd archivo.
$ awk -F ':' '{ print $1 }' /etc/passwd | sort Puede cambiar fácilmente el orden de clasificación modificando el comando de clasificación.
38. Imprima la página del manual
La página del manual contiene información detallada del comando awk junto con todas las opciones disponibles. Es extremadamente importante para las personas que quieren dominar a fondo el comando awk.
$ man awk
Si desea aprender funciones complejas de awk, esto le será de gran ayuda. Consulte esta documentación cada vez que tenga un problema.
39. Imprima la página de ayuda
La página de ayuda contiene información resumida de todos los posibles argumentos de la línea de comandos. Puede invocar la guía de ayuda para awk usando uno de los siguientes comandos.
$ awk -h $ awk --help
Consulte esta página si desea obtener una descripción general rápida de todas las opciones disponibles para awk.
40. Información de la versión impresa
La información de la versión nos proporciona información sobre la compilación de un programa. La página de la versión de awk contiene información como sus derechos de autor, herramientas de compilación, etc. Puede ver esta información usando uno de los siguientes comandos awk.
$ awk -V $ awk --version
Pensamientos finales
El comando awk en Linux nos permite hacer todo tipo de cosas, incluido el procesamiento de archivos y el mantenimiento del sistema. Proporciona una amplia gama de operaciones para manejar las tareas informáticas del día a día con bastante facilidad. Nuestros editores han compilado esta guía con 40 útiles comandos awk que se pueden usar para la manipulación o administración de texto. Dado que AWK es un lenguaje de programación completo por sí mismo, existen múltiples formas de hacer el mismo trabajo. Entonces, no se pregunte por qué estamos haciendo ciertas cosas de una manera diferente. Siempre puede seleccionar sus propias recetas en función de su conjunto de habilidades y experiencia. Déjanos tu opinión, avísanos si tienes alguna pregunta.