Apache Hadoop es un marco de código abierto que se utiliza para administrar, almacenar y procesar datos para varias aplicaciones de big data que se ejecutan en sistemas agrupados. Está escrito en Java con algo de código nativo en C y scripts de shell. Utiliza un sistema de archivos distribuido (HDFS) y escala desde servidores individuales a miles de máquinas.
Apache Hadoop se basa en cuatro componentes principales:
- Común de Hadoop: Es la colección de utilidades y bibliotecas que necesitan otros módulos de Hadoop.
- HDFS: También conocido como sistema de archivos distribuidos de Hadoop distribuido en varios nodos.
- MapReduce : Es un marco utilizado para escribir aplicaciones para procesar grandes cantidades de datos.
- HADOOP HILO: También conocida como Yet Another Resource Negotiator, es la capa de administración de recursos de Hadoop.
En este tutorial, explicaremos cómo configurar un clúster de Hadoop de un solo nodo en Ubuntu 20.04.
Requisitos
- Un servidor con Ubuntu 20.04 con 4 GB de RAM.
- Se ha configurado una contraseña raíz en su servidor.
Actualizar los paquetes del sistema
Antes de comenzar, se recomienda actualizar los paquetes de su sistema a la última versión. Puedes hacerlo con el siguiente comando:
apt-get update -y
apt-get upgrade -y
Una vez que su sistema esté actualizado, reinícielo para implementar los cambios.
Instalar Java
Apache Hadoop es una aplicación basada en Java. Por lo tanto, deberá instalar Java en su sistema. Puede instalarlo con el siguiente comando:
apt-get install default-jdk default-jre -y
Una vez instalado, puede verificar la versión instalada de Java con el siguiente comando:
java -version
Deberías obtener el siguiente resultado:
openjdk version "11.0.7" 2020-04-14 OpenJDK Runtime Environment (build 11.0.7+10-post-Ubuntu-3ubuntu1) OpenJDK 64-Bit Server VM (build 11.0.7+10-post-Ubuntu-3ubuntu1, mixed mode, sharing)
Crear usuario de Hadoop y configurar SSH sin contraseña
Primero, cree un nuevo usuario llamado hadoop con el siguiente comando:
adduser hadoop
A continuación, agregue el usuario de hadoop al grupo sudo
usermod -aG sudo hadoop
A continuación, inicie sesión con el usuario hadoop y genere un par de claves SSH con el siguiente comando:
su - hadoop
ssh-keygen -t rsa
Deberías obtener el siguiente resultado:
Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub The key fingerprint is: SHA256:HG2K6x1aCGuJMqRKJb+GKIDRdKCd8LXnGsB7WSxApno [email protected] The key's randomart image is: +---[RSA 3072]----+ |..=.. | | O.+.o . | |oo*.o + . o | |o .o * o + | |o+E.= o S | |=.+o * o | |*.o.= o o | |=+ o.. + . | |o .. o . | +----[SHA256]-----+
A continuación, agregue esta clave a las claves ssh autorizadas y otorgue el permiso adecuado:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
A continuación, verifique el SSH sin contraseña con el siguiente comando:
ssh localhost
Una vez que haya iniciado sesión sin contraseña, puede continuar con el siguiente paso.
Instalar Hadoop
Primero, inicie sesión con el usuario hadoop y descargue la última versión de Hadoop con el siguiente comando:
su - hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
Una vez que se complete la descarga, extraiga el archivo descargado con el siguiente comando:
tar -xvzf hadoop-3.2.1.tar.gz
A continuación, mueva el directorio extraído a /usr/local/:
sudo mv hadoop-3.2.1 /usr/local/hadoop
A continuación, cree un directorio para almacenar el registro con el siguiente comando:
sudo mkdir /usr/local/hadoop/logs
A continuación, cambie la propiedad del directorio hadoop a hadoop:
sudo chown -R hadoop:hadoop /usr/local/hadoop
A continuación, deberá configurar las variables de entorno de Hadoop. Puede hacerlo editando el archivo ~/.bashrc:
nano ~/.bashrc
Agregue las siguientes líneas:
export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Guarde y cierre el archivo cuando haya terminado. Luego, active las variables de entorno con el siguiente comando:
source ~/.bashrc
Configurar Hadoop
En esta sección, aprenderemos cómo configurar Hadoop en un solo nodo.
Configurar variables de entorno Java
A continuación, deberá definir las variables de entorno de Java en hadoop-env.sh para configurar los ajustes del proyecto relacionados con YARN, HDFS, MapReduce y Hadoop.
Primero, ubique la ruta correcta de Java usando el siguiente comando:
which javac
Debería ver el siguiente resultado:
/usr/bin/javac
A continuación, busque el directorio OpenJDK con el siguiente comando:
readlink -f /usr/bin/javac
Debería ver el siguiente resultado:
/usr/lib/jvm/java-11-openjdk-amd64/bin/javac
A continuación, edite el archivo hadoop-env.sh y defina la ruta de Java:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Agregue las siguientes líneas:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
A continuación, también deberá descargar el archivo de activación de Javax. Puedes descargarlo con el siguiente comando:
cd /usr/local/hadoop/lib
sudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jar
Ahora puede verificar la versión de Hadoop usando el siguiente comando:
hadoop version
Deberías obtener el siguiente resultado:
Hadoop 3.2.1 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842 Compiled by rohithsharmaks on 2019-09-10T15:56Z Compiled with protoc 2.5.0 From source with checksum 776eaf9eee9c0ffc370bcbc1888737 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.2.1.jar
Configurar archivo core-site.xml
A continuación, deberá especificar la URL de su NameNode. Puede hacerlo editando el archivo core-site.xml:
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml
Agregue las siguientes líneas:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:9000</value>
<description>The default file system URI</description>
</property>
</configuration>
Guarde y cierre el archivo cuando haya terminado:
Configurar archivo hdfs-site.xml
A continuación, deberá definir la ubicación para almacenar los metadatos del nodo, el archivo fsimage y el archivo de registro de edición. Puede hacerlo editando el archivo hdfs-site.xml. Primero, cree un directorio para almacenar los metadatos del nodo:
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfs A continuación, edite el archivo hdfs-site.xml y defina la ubicación del directorio:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Agregue las siguientes líneas:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
Guarde y cierre el archivo.
Configurar archivo mapred-site.xml
A continuación, deberá definir los valores de MapReduce. Puede definirlo editando el archivo mapred-site.xml:
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Agregue las siguientes líneas:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Guarde y cierre el archivo.
Configurar archivo yarn-site.xml
A continuación, deberá editar el archivo yarn-site.xml y definir la configuración relacionada con YARN:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Agregue las siguientes líneas:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Guarde y cierre el archivo cuando haya terminado.
Formatear HDFS NameNode
A continuación, deberá validar la configuración de Hadoop y formatear el NameNode de HDFS.
Primero, inicie sesión con el usuario de Hadoop y formatee el NameNode de HDFS con el siguiente comando:
su - hadoop
hdfs namenode -format
Deberías obtener el siguiente resultado:
2020-06-07 11:35:57,691 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,692 INFO util.GSet: 0.25% max memory 1.9 GB = 5.0 MB 2020-06-07 11:35:57,692 INFO util.GSet: capacity = 2^19 = 524288 entries 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 2020-06-07 11:35:57,712 INFO util.GSet: Computing capacity for map NameNodeRetryCache 2020-06-07 11:35:57,712 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,712 INFO util.GSet: 0.029999999329447746% max memory 1.9 GB = 611.9 KB 2020-06-07 11:35:57,712 INFO util.GSet: capacity = 2^16 = 65536 entries 2020-06-07 11:35:57,743 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1242120599-69.87.216.36-1591529757733 2020-06-07 11:35:57,763 INFO common.Storage: Storage directory /home/hadoop/hdfs/namenode has been successfully formatted. 2020-06-07 11:35:57,817 INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 2020-06-07 11:35:57,972 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 398 bytes saved in 0 seconds . 2020-06-07 11:35:57,987 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2020-06-07 11:35:58,000 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown. 2020-06-07 11:35:58,003 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at ubuntu2004/69.87.216.36 ************************************************************/
Iniciar el clúster de Hadoop
Primero, inicie NameNode y DataNode con el siguiente comando:
start-dfs.sh
Deberías obtener el siguiente resultado:
Starting namenodes on [0.0.0.0] Starting datanodes Starting secondary namenodes [ubuntu2004]
A continuación, inicie el recurso YARN y los administradores de nodos ejecutando el siguiente comando:
start-yarn.sh
Deberías obtener el siguiente resultado:
Starting resourcemanager Starting nodemanagers
Ahora puede verificarlos con el siguiente comando:
jps
Deberías obtener el siguiente resultado:
5047 NameNode 5850 Jps 5326 SecondaryNameNode 5151 DataNode
Acceder a la interfaz web de Hadoop
Ahora puede acceder al NameNode de Hadoop usando la URL http://your-server-ip:9870. Debería ver la siguiente pantalla:
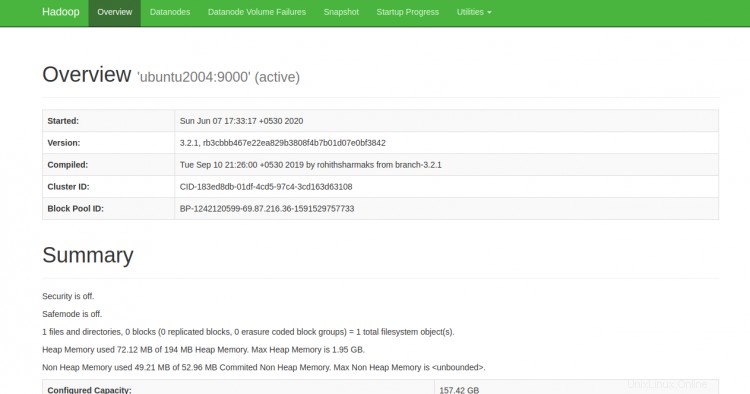
También puede acceder a los DataNodes individuales utilizando la URL http://your-server-ip:9864. Debería ver la siguiente pantalla:
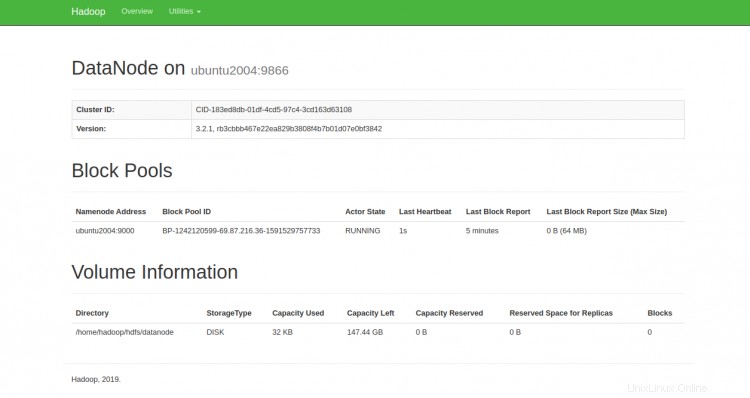
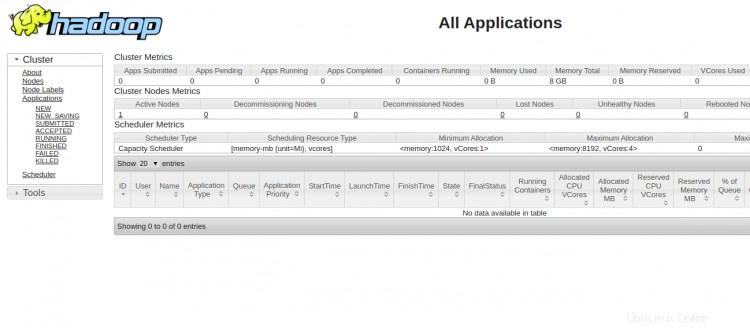
Para acceder al Administrador de recursos de YARN, use la URL http://your-server-ip:8088. Debería ver la siguiente pantalla:
Conclusión
¡Felicidades! Ha instalado correctamente Hadoop en un solo nodo. Ahora puede comenzar a explorar los comandos básicos de HDFS y diseñar un clúster de Hadoop completamente distribuido. Siéntase libre de preguntarme si tiene alguna pregunta.