Apache Hadoop es un marco de software gratuito de código abierto escrito en Java para el almacenamiento distribuido y el procesamiento de grandes datos mediante MapReduce. Maneja conjuntos de datos de gran tamaño dividiéndolos en grandes bloques y distribuyéndolos entre las computadoras en un clúster.
En lugar de depender de clústeres de SO estándar, los módulos de Hadoop están diseñados para detectar y administrar la falla en la capa de la aplicación y brindarle un servicio de alta disponibilidad a nivel de software.
El marco base de Hadoop consta de los siguientes módulos,
- Común de Hadoop – Contiene un conjunto común de bibliotecas y utilidades para admitir otros módulos de Hadoop
- Sistema de archivos distribuidos de Hadoop (HDFS) – Sistema de archivos distribuido basado en Java que almacena datos en hardware estándar, proporcionando un rendimiento muy alto a la aplicación.
- HILO de Hadoop – Administra los recursos en los clústeres de cómputo y los usa para programar las aplicaciones del usuario.
- Hadoop MapReduce – Marco para el procesamiento de datos a gran escala basado en el modelo de programación MapReduce.
En esta publicación, veremos cómo instalar Apache Hadoop en RHEL 8.
Requisitos
Cambie al usuario root.
su -
O
sudo su -
Apache Hadoop v3.1.2 solo es compatible con la versión 8 de Java. Por lo tanto, instale OpenJDK 8 u Oracle JDK 8.
En esta demostración, usaré OpenJDK 8.
yum -y instalar java-1.8.0-openjdk wget
Compruebe la versión de Java.
java-versión
Salida:
openjdk versión "1.8.0_201" OpenJDK Runtime Environment (compilación 1.8.0_201-b09)OpenJDK 64-Bit Server VM (compilación 25.201-b09, modo mixto)
Instalar Apache Hadoop en RHEL 8
Crear usuario de Hadoop
Se recomienda ejecutar Apache Hadoop por un usuario regular. Entonces, aquí, crearemos un usuario llamado hadoop y estableceremos una contraseña para el usuario.
useradd -m -d /home/hadoop -s /bin/bash hadooppasswd hadoop
Ahora, configure ssh sin contraseña para el sistema local siguiendo los pasos a continuación.
# su - hadoop$ ssh-keygen$ cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys$ chmod 600 ~/.ssh/authorized_keys
Verifique la comunicación sin contraseña con su sistema local.
$ ssh 127.0.0.1
Salida:
Si se conecta a través de ssh por primera vez, deberá escribir sí para agregar claves RSA a hosts conocidos.
[hadoop@rhel8 ~]$ ssh 127.0.0.1 No se puede establecer la autenticidad del host '127.0.0.1 (127.0.0.1)'. La huella digital de la clave ECDSA es SHA256:85jUAgtJg8RLOqs8T2egxF7U7IWIiYF+CRspO8yatAk. ¿Está seguro de que desea continuar conectándose (sí/no)? Sí Advertencia:se agregó permanentemente '127.0.0.1' (ECDSA) a la lista de hosts conocidos. Active la consola web con:systemctl enable --now cockpit.socket Último inicio de sesión:miércoles 8 de mayo 12:15:04 2019 desde 127.0.0.1 [hadoop @rhel8 ~]$
Descarga Hadoop
Visite la página de Apache Hadoop para descargar la última versión de Apache Hadoop (siempre elija la versión que esté lista para producción consultando la documentación), o puede usar el siguiente comando en la terminal para descargar Hadoop v3.1.2.
$ wget https://www-us.apache.org/dist/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz$ tar -zxvf hadoop-3.1.2.tar. gz $ mv hadoop-3.1.2 hadoop
Tipos de clústeres de Hadoop
Hay tres tipos de clústeres de Hadoop:
- Modo local (independiente) – Se ejecuta como un único proceso java.
- Modo pseudodistribuido – Cada demonio de Hadoop se ejecuta como un proceso separado.
- Modo Totalmente Distribuido – un clúster multinodo. Desde unos pocos nodos hasta un clúster extremadamente grande.
Configurar variables ambientales
Aquí, configuraremos Hadoop en modo pseudodistribuido. Primero, configuraremos las variables ambientales en el archivo ~/.bashrc.
Cambie las entradas de las variables JAVA_HOME y HADOOP_HOME en el archivo según su entorno.exportar JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.201.b09-2.el8.x86_64/ exportar HADOOP_HOME=/inicio/hadoop/hadoop exportar hadoop_install =$ hadoop_homeexport hadoop_mapred_home =$ hadoop_homeexport hadoop_common_home =$ hadoop_homeexportAplique variables ambientales a su sesión de terminal actual.
$ fuente ~/.bashrcConfigurar Hadoop
Edite el archivo ambiental de Hadoop y actualice la variable como se muestra a continuación.
$ vi $HADOOP_HOME/etc/hadoop/hadoop-env.shActualice la variable JAVA_HOME según su entorno.
exportar JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.201.b09-2.el8.x86_64/Ahora editaremos los archivos de configuración de Hadoop según el modo de clúster que configuremos (pseudodistribuido).
$ cd $HADOOP_HOME/etc/hadoopEdite core-site.xml y actualice el archivo con el nombre de host HDFS.
fs.defaultFS hdfs://rhel8.itzgeek.local :9000 Cree los directorios namenode y datanode en el directorio home /home/hadoop del usuario de hadoop.
$ mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}Edite hdfs-site.xml y actualice el archivo con la información del directorio NameNode y DataNode.
dfs.replicación 1 dfs.nombre.dir archivo :///home/hadoop/hadoopdata/hdfs/namenode dfs.data.dir file:///home/hadoop/hadoopdata/hdfs/datanode Edite mapred-site.xml.
mapreduce.framework.name hilo Edite yarn-site.xml.
yarn.nodemanager.aux-services mapreduce_shuffle Formatee el NameNode usando el siguiente comando.
$ hdfs namenode -formatoSalida:
. . .. . .2019-05-13 19:33:14,720 INFO namenode.FSImage:nuevo BlockPoolId asignado:BP-1601223288-192.168.1.10-15577561946432019-05-13 19:33:15,100 INFO common.Storage:directorio de almacenamiento /home/hadoop/ hadoopdata/hdfs/namenode se ha formateado correctamente.2019-05-13 19:33:15,436 INFO namenode.FSImageFormatProtobuf:guardando el archivo de imagen /home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_00000000000000000000 sin compresión2019-05- 13 19:33:16,804 INFO namenode.FSImageFormatProtobuf:Archivo de imagen /home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 de tamaño 393 bytes guardado en 1 segundo .2019-05-13 19:33:17,106 INFO namenode .NNStorageRetentionManager:Voy a retener 1 imágenes con txid>=02019-05-13 19:33:17,150 INFO namenode.NameNode:SHUTDOWN_MSG:/******************** **************************************** SHUTDOWN_MSG:Cerrando NameNode en rhel8.itzgeek. local/192.168.1.10************************************************ ***************/Cortafuegos
Ejecute los siguientes comandos para permitir las conexiones de Apache Hadoop a través del firewall. Ejecute estos comandos como usuario root.
firewall-cmd --permanent --add-port=9870/tcpfirewall-cmd --permanent --add-port=8088/tcpfirewall-cmd --recargarIniciar Hadoop &Yarn
Inicie los demonios NameNode y DataNode utilizando los scripts proporcionados por Hadoop.
$ inicio-dfs.shSalida:
Inicio de namenodes en [rhel8.itzgeek.local]rhel8.itzgeek.local:Advertencia:Se agregó permanentemente 'rhel8.itzgeek.local,fe80::4480:83a5:c52:ea80%enp0s3' (ECDSA) a la lista de hosts conocidos.Iniciando datanodeslocalhost:Advertencia:'localhost' (ECDSA) agregado permanentemente a la lista de hosts conocidos.Iniciando namenodes secundarios [rhel8.itzgeek.local]2019-05-13 19:39:00,698 WARN util.NativeCodeLoader:No se puede cargue la biblioteca nativa-hadoop para su plataforma... usando clases java integradas cuando correspondaAbra un navegador y vaya a la siguiente dirección para acceder a Namenode.
http://ip.ad.dre.ss:9870/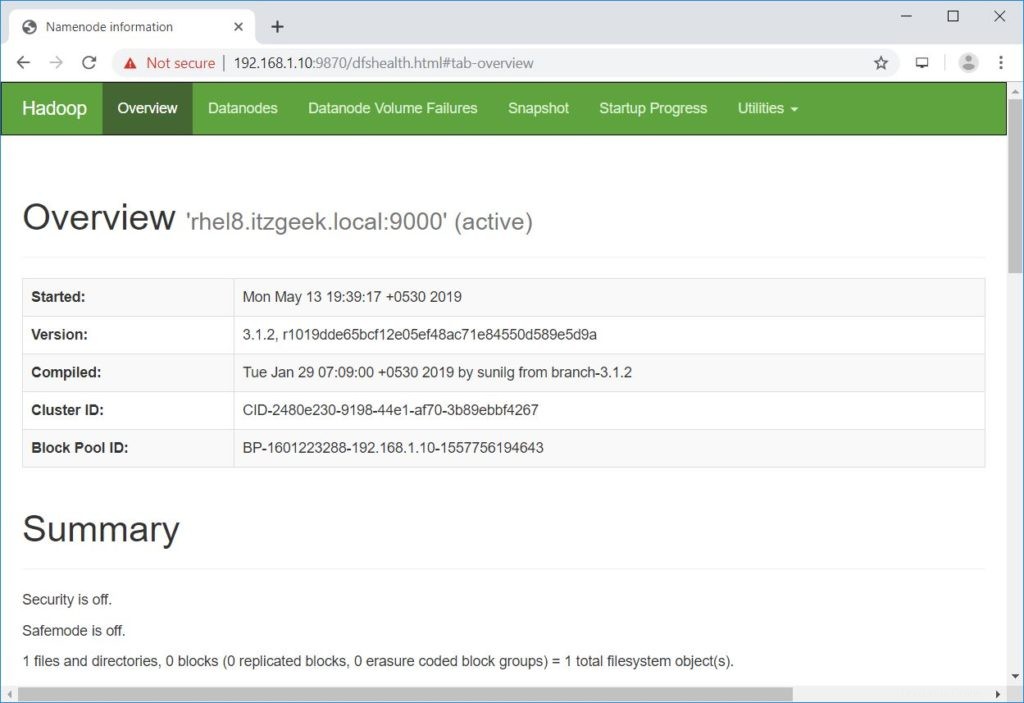
Inicie ResourceManager y NodeManagers.
$ inicio-hilo.shSalida:
Iniciando resourcemanagerIniciando nodemanagersAbra un navegador y vaya a la siguiente dirección para acceder a ResourceManager.
http://ip.ad.dre.ss:8088/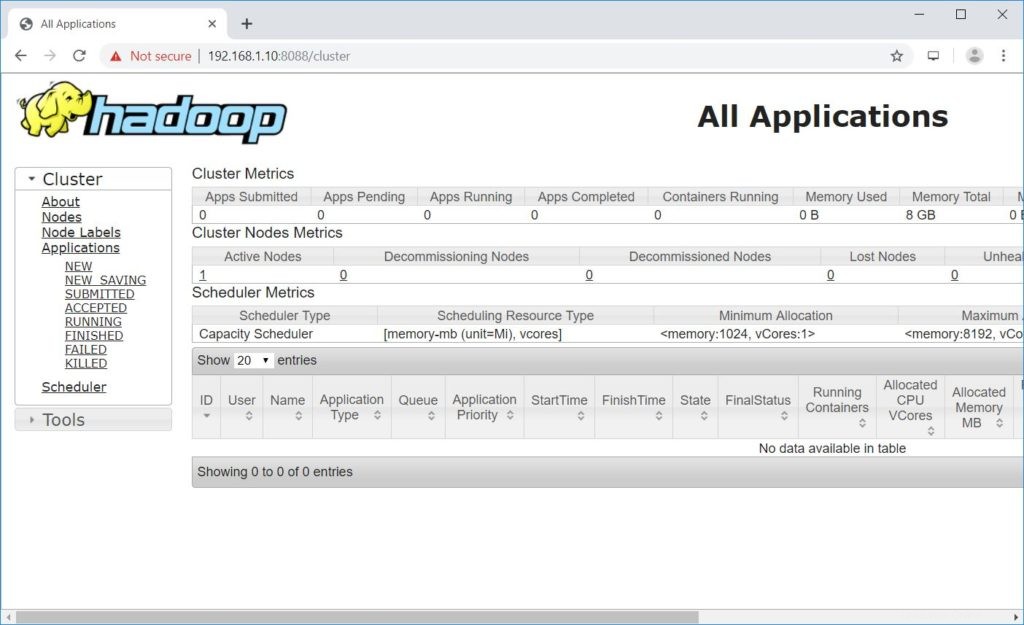
Prueba Apache Hadoop
Ahora probaremos Apache Hadoop cargando un archivo de muestra en él. Antes de cargar un archivo en HDFS, cree un directorio en HDFS.
$ hdfs dfs-mkdir /rajVerifique que el directorio creado exista en HDFS.
hdfs dfs -lsSalida:
Encontrados 1 elementosdrwxr-xr-x - hadoop supergroup 0 2019-05-08 13:20 /rajCargue un archivo en el directorio HDFS raj con el siguiente comando.
$ hdfs dfs -put ~/.bashrc /rajLos archivos cargados se pueden ver ejecutando el siguiente comando.
$ hdfs dfs -ls /rajO
Ir a NombreNodo>> Utilidades>> Explorar el sistema de archivos en NodoNombre.
http://ip.ad.dre.ss:9870/explorer.html#/raj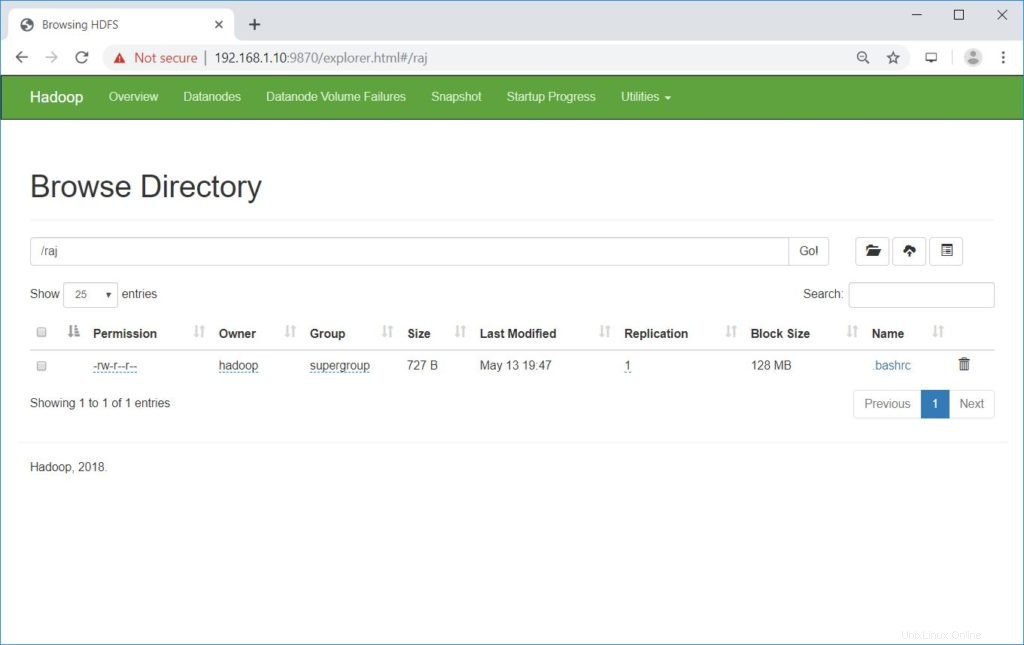
Puede copiar los archivos de HDFS a sus sistemas de archivos locales usando el siguiente comando.
$ hdfs dfs -get /raj /tmp/Si es necesario, puede eliminar los archivos y directorios en HDFS usando los siguientes comandos.
$ hdfs dfs -rm -f /raj/.bashrc$ hdfs dfs -rmdir /rajConclusión
Espero que esta publicación lo haya ayudado a instalar y configurar un clúster Apache Hadoop de un solo nodo en RHEL 8. Puede leer la documentación oficial de Hadoop para obtener más información. Comparta sus comentarios en la sección de comentarios.